Around the 🌎 with Unicode
Unicode is really exciting, because it lets software handle two things:
- Emoji. 🎉
- All written human language1.
The first point is obviously the most important, but the second is also pretty interesting. It turns out that cultures and languages are complicated, which means writing systems are complicated, which means that the Unicode standard is also complicated. It also turns out that character encoding standards aren’t value-neutral. This blog post is a very informal survey of some cool, interesting and surprising things about Unicode.
What is Unicode?
Computers store all data as a series of bits, and this obviously includes text. So computers need to know which series of bits corresponds to which character. Back in Ye Olden Times most systems in English-speaking countries used ASCII, which encoded each character using 7 bits. 27 is 128, so you could encode 128 characters. That was plenty for every upper- and lowercase letter, numbers, punctuation, the space character, and so on. A byte is 8 bits, so one ASCII character fits conveniently in a single byte. This was less than ideal if your application had to handle recipes for soufflés, piña coladas, or spätzle, and it was completely unworkable for people who used non-Latin alphabets. So there were a bunch of other encodings for different alphabets, and it was basically impossible to write software that could handle text in more than one language (unless, maybe, one of those languages was English).
So now we have Unicode, which maps every single character in every writing system to a unique number, called a code point. (Each emoji is assigned a code point too.) There are a few different ways to translate code points into actual bits, the most common being UTF-82. If you support Unicode, you don’t need different encodings for different languages – you can handle text in any language or mix of languages, uniformly and with no fuss. As long as you use Unicode all the time, everything is easy!
This is a lie. Nothing in life is easy.
Diacritical Marks
We need a way to distinguish between a, à, á, â, ä and å. Should each one get its own code point? It seems excessive to have a separate code point for every possible letter/diacritic combination. Unicode handles this with combining marks – you have one code point for the base letter and one for the diacritical mark. The code point for “a” is 0061, and the code point for COMBINING ACUTE ACCENT is 0301, so U+0061 U+0301 should render as á.
>>> accent="\u0301" #accent code point
>>> accent
'́'
>>> a="a"
>>> a+accent
'á'
But a lot of pre-Unicode systems were using ISO 8859-1, which was basically an extended, 8-bit ASCII, which already HAD an á character at code point e1. To maintain compatibility with those systems, Unicode kept these “precomposed” characters, which means the same character can be represented in multiple ways:
>>> accented_one="\u00e1"
>>> accented_two="\u0061"+"\u0301"
>>> accented_one
'á'
>>> accented_two
'á'
>>> accented_one == accented_two
False
Combining marks have a ton of uses, some more esoteric than others. Here are a few of them:
-
The many, many diacritics in the International Phonetic Alphabet
IPA notation for “croissant”: krwɑːˈsɒ
-
Cantillation marks in Hebrew, indicating how Biblical passages should be chanted.
Opening words of Genesis (“In the beginning, God created…”) with cantillation: בְּרֵאשִׁ֖ית בָּרָ֣א אֱלֹהִ֑ים
-
Honorifics in Arabic, most of which are placed over the names of religious figures. These are interesting because they’re combining characters for whole words, rather than individual characters.
Name of Abu Bakr – the ‘ ؓ ‘ character is the honorific “may God be pleased with him”: أبو بكرؓ
-
Ancient Greek editorial marks used by scribes to denote that they added a missing diacritical mark, or removed an erroneous one.
A fragment of Greek poetry3 – the ᷀ is the editorial mark: αρετα҄᷀σαπολ
-
Emoji skin tone modifiers.
>>> "👨"+"🏽" '👨🏽'
Ligatures
Sometimes two characters are written as a single unit called a ligature – like æ and œ. The official Unicode stance is that ligatures shouldn’t get their own code points – it’s up to your font and rendering engine to determine whether to display “oe” or “œ”. As with diacritical marks, Unicode has a bunch of precomposed ligatures for compatibility reasons, but that doesn’t mean they’re happy about it.
The existing ligatures exist basically for compatibility and round-tripping with non-Unicode character sets. Their use is discouraged. No more will be encoded in any circumstances. -Unicode FAQ on Ligatures, Digraphs, and Presentation Forms
So, given two or more code points, a rendering engine needs to decide whether to display them separately or as a ligature – and, if it’s the latter, your font needs to actually include that ligature. This gets complicated because you can’t always tell just from the text itself whether two characters should be connected – for example, letters that would normally be joined in Arabic sometimes shouldn’t be joined in Persian. To deal with this, Unicode has a zero-width joiner (U+200D) to indicate two characters should be displayed as a ligature, even if they normally wouldn’t be, AND a zero-width non-joiner (U+200C), which indicates that two characters should be displayed separately even if they would normally be a ligature.
Devanagari uses a virama (्), rather than a zero-width joiner, to indicate that consonants should form a ligature (also called a consonant cluster)…but Devanagari also sometimes uses zero-width joiners too.
>>> "त"+"व"
>>> "त"+"्"+"व"
'त्व'
The zero-width joiner can also be used to create emoji ligatures:
>>> zwj = "\u200d"
>>> a="👨"+zwj+"⚕️"
>>> print(a)
👨⚕️
>>> family="👨"+zwj+"👨"+zwj+"👦"+zwj+"👦"
>>> print(family)
👨👨👦👦
Han Unification
A large set of Han characters, called CJK characters, are shared between Chinese, Japanese, Korean and Vietnamese. Because they look almost the same and mean the same thing in all four languages, each of these characters is given a single code point, rather than one code point per language. The problem is, some Han characters vary between languages4. So, in order to display a CJK character correctly, you need to know which language it’s in, which means you need to rely on extra information outside of the text itself – like the user’s locale or the HTML “lang” attribute. This significantly reduces the number of code points you need, and simplifies normalizing and collating CJK text, at the expense of undermining the entire point of Unicode.
I am, possibly, being unfair to Unicode here – you can definitely make the historical/cultural/philosophical argument that Han characters are fundamentally the same across all languages, which is exactly what the Unicode consortium does. And you probably want two strings to be equal if they’re just using different language variants of the same character. On the other hand…there’s this quote right at the top of the What is Unicode? page on their website:
Unicode provides a unique number for every character, no matter what the platform, no matter what the program, no matter what the language.
which seems to run counter to the idea that some arguably-different characters have to share numbers.
Anyway, there’s actually a solution to this, which seems pretty elegant in my definitely-not-expert opinion. You can use a special character called a variation selector to specify which version of a CJK glyph to use. In practice, though, I’m not sure that variation sequences are widely used – most characters don’t have any defined variants. And my computer, at least, doesn’t seem to respect the variation sequences that are defined – characters rendered exactly the same way regardless of the variation selector. But I might just not have the right fonts installed.
Hard Questions in Unicode
Are two strings the same?
Like we saw earlier, the precomposed and combined form of a character can be different, even if they look identical:
>>> accented_one="\u00e1"
>>> accented_two="\u0061"+"\u0301"
>>> accented_one
'á'
>>> accented_two
'á'
>>> accented_one == accented_two
False
To handle this properly, you need to convert both strings into the same normalized form, using a normalization algorithm defined in the Unicode standard:
>>> one="\u00e1"
>>> two = "\u0061"+"\u0301"
>>> one
'á'
>>> two
'á'
>>> one==two
False
>>> from unicodedata import normalize
>>> one_norm = normalize('NFC', one)
>>> two_norm = normalize('NFC', two)
>>> one_norm == two_norm
True
This doesn’t always work, though: you can add multiple combining characters to one letter. The order of combining characters will impact whether two strings are equal – even if they look identical. Normalizing a string sometimes changes the order of diacritics, and sometimes doesn’t5.
>>> s="כ\u05bc\u05b4" # apply two Hebrew niqqud (vowel/pronunication markings)
>>> s
'כִּ'
>>> t="כ\u05b4\u05bc" # apply the same niqqud in a different order
>>> t
'כִּ'
>>> s==t
False
>>> from unicodedata import normalize
>>> normalize('NFC', s) == normalize('NFC', t) # niqqud are normalized into canonical form
True
>>> one="a"+"\u0301"+"\u0304" #add macron and accent to letter a
>>> two="a"+"\u0304"+"\u0301" #add them in opposite order
>>> one
'á̄'
>>> two # it looks different!
'ā́'
>>> normalize('NFC',one) == normalize('NFC',two) # even after normalization they look different
False
It makes sense that these wouldn’t normalize to the same value because they’re different characters…but it is one more edge case to consider.
Also, Latin characters are not equivalent to their fullwidth counterparts:
>>> full="\uff21"
>>> full
'A'
>>> full=="A"
False
>>> normalize('NFC',full) == normalize('NFC',"A")
False
How long is a string?
Again, it depends on whether you’re using the combining or precomposed form of a character. It also depends on whether “length” means “number of bytes,” “number of code points,” or “number of characters according to the end user.”
The python 2 len function returns length in bytes by default. Python 3 returns length in code points.
$ python -c "print(len('𐊃'))" #a character from ancient Lycian (U+10283)
4
$ python3 -c "print(len('𐊃'))"
1
JavaScript returns the number of UTF-16 code units, which is usually the same as the number of code points, but gives surprising results for code points higher than U+FFFF.
> "𐊃".length
2
None of these necessarily correspond to how many separate characters a human might recognize on the screen.
How do you sort things in alphabetical order?
There’s some fiddliness here with combining marks, zero-width joiners and so on, but the real issue is that different languages use different collations, even if they use the same script. For example, ö comes after z in Swedish, but in most other languages that use Latin scripts it should come right after o. Also, in some languages certain pairs of letters (called digraphs) are considered a single letter, which means they need to be treated accordingly for collation – in Slovak, for example, “ch” is a separate letter that comes after “h”, but it’s still represented by the code points for “c” and “h”6.
You should sort text based on who’s looking at it, not based on what language it’s in (and you might not know what language it’s in anyway). If I’m looking at an alphabetical list of names, I should see them in what I think of as alphabetical order, even if those people are from many different countries. So collation is locale-sensitive:
> "ch".localeCompare("ct");
-1
> "ch".localeCompare("ct","sk"); // Slovakian locale
1
I used JavaScript for this example because Python handles collation incorrectly on OS X and BSD.
Ghosts of Languages Past
In the string length example above, I used a character from ancient Lycian. Unicode encodes a lot of historic scripts and punctuation, so that historical texts can be digitized correctly. Here are a few of them:
(Some of these characters might not display in your browser, so I’ve also included them as images. They might still display if you paste them into a text editor or terminal. You should try it, seeing hieroglyphics in your terminal is kind of awesome.)
-
Linear B, an ancient Mycenaean script, famously deciphered in the 1950s
Code point Character Image U+10000 𐀀 
U+10001 𐀁 
U+10002 𐀃 
-
Code point Character Image U+13000 𓀀 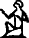
U+13001 𓀁 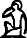
U+13002 𓀂 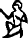
-
Nüshu, a script used only by women in Southern China
Code point Character Image U+1B170 𛅰 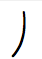
U+1B171 𛅱 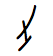
U+1B172 𛅲 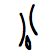
-
Runic, used by early and medieval Germanic, Scandinavian, and Anglo-Saxon people
Code point Character Image U+16A0 ᚠ 
U+16A2 ᚢ 
U+16A3 ᚦ 
But a lot of historic scripts and symbols haven’t been encoded yet. The folks at the Medieval Unicode Font Initiative are working on adding more medieval Latin symbols, and the Script Encoding Initiative at Berkeley is trying to get more historic (and living!) scripts encoded.
Private Use Areas (Here there be Elves)
A few blocks of code points are defined as Private Use Areas – Unicode won’t assign any code points in those areas, so software can interpret them however it likes. The ConScript Unicode Registry has assigned Private Use Area code points to a bunch of fictional scripts, including:
- Tengwar (the Elvish script in Tolkien)
- Klingon7
- The “Seussian Latin Extensions”, extra letters of the alphabet from a Dr. Seuss book
- D’ni, the language/civilization in Myst
Sadly, my computer doesn’t seem to have rendering support for any of these.
BRAKCET
The Unicode standard makes certain promises about stability – one of these promises is that the names of code points will never change, no matter what. Because of this rule, code point U+FE18 in the Vertical Forms block will be forever known as PRESENTATION FORM FOR VERTICAL RIGHT WHITE LENTICULAR BRAKCET.
Further Reading/Watching
- “💩”.length === 2
- !!Con 2016 – My favorite Unicode character: the zero-width joiner!
- I Can Text You A Pile of Poo, But I Can’t Write My Name. I also found the accompanying Hacker News discussion helpful, even though a lot of the comments are terrible because it’s Hacker News.
- The secret life of Unicode
- Polytonic Greek Unicode Still Isn’t Perfect makes some interesting points about how combining characters interfere with syllabification and other text processing.
- Best bits of the web, which provided the original inspiration for this blog post.
- The Unicode Standard, Version 10.0.0, in all its glory.
1 At least, that’s the goal – but a lot of scripts haven’t been encoded yet. ↩
2 Short explanation: a UTF-8 code point uses between one and four bytes. The first few bits of a code point tell you how many bytes it will be. ↩
3 Taken from the Examples section of the proposal to add an encoding for this character. ↩
4 Simplified and traditional Chinese also use different variants. ↩
5 Source: Polytonic Greek Unicode Still Isn’t Perfect. ↩